Bash最佳实践:awk? awk!
摘要
awk 是 Unix-like 系统上最强大的文本处理工具,其灵活的语法和丰富的功能使其可以优雅方便地处理各种文本任务。
本文系统性的介绍了AWK的语法和执行流程,并给出了实际使用场景的案例。适用于对 awk 不了解的读者。
名词解释
- awk:小写,指操作系统上面的
awk命令 - AWK:大写,指 《AWK程序设计语言》
引言
AWK 这个名字取自其发明者 Alfred Aho , Peter J. Weinberger 和 Brian Kernighan 的姓氏的首个字母组成。
awk 命令在我们的使用场景中,一般用作取文本输出的具体列,比如查找 chrome 浏览器相关的 PID1。
| |
命令语句先 grep chrome 相关的进程,然后使用 awk 取过滤后文本的第2列。
这个命令语句能正常工作,但有些别扭,使用了两次 grep,awk 命令只用到了最基本的,取文本列的功能。
但如果我们了解 awk,使用 awk 的高级特性可以让事情变的简单优雅。
本示例中,可以用 awk 的过滤模式来取代 grep 的过滤功能,命令优化为
| |
优化后的示例中,ps 命令只输出 pid 和 command 列,awk 命令直接过滤带有 Google Chrome 的行并打印该行的第一列,避免了两次
grep 命令的调用。
笔者曾使用 awk 优化重构过直接在 bash 中使用 for if grep awk sed 等命令解析文本的脚本,
由于优化前需要在多个命令中来回切换文本解析的上下文,重构后整个上下文均在 awk 命令中完成,减少的命令调用与上下文切换,
使脚本的运行速率直接提升了一个数量级!
另外我想借此示例明确表达的一点是,awk 命令同 bash 命令一样,是一个脚本解释器,有完整的
AWK 程序编程语法
,AWK 的三位发明者将其定义为
样式扫描和处理语言
,适用于文本分析处理场景。
示例中的 '/Google Chrome/{print $1}' 就是一段 AWK 脚本,简短的脚本内容一般通过命令行参数传入给 awk 解释器,
较长的 AWK 脚本可以写入到文件,如 xxx.awk,然后通过 awk -f xxx.awk 执行脚本逻辑,或者给 AWK
脚本添加可执行权限后直接调用,
示例
。
简而言之,AWK 是一种用于处理文本的编程语言工具,awk 是该语言的解释器。
概览
AWK reads the input a line at a time. A line is scanned for each pattern in the program, and for each pattern that matches, the associated action is executed.
— Alfred Aho
脚本结构
AWK 脚本的程序结构分别由 Function block BEGIN block Common Statement block END block
四个块组成,这四个块都是可选的,Common Statement block 包含 pattern 和 commands 两部分,均可缺省。
一个示例:
| |
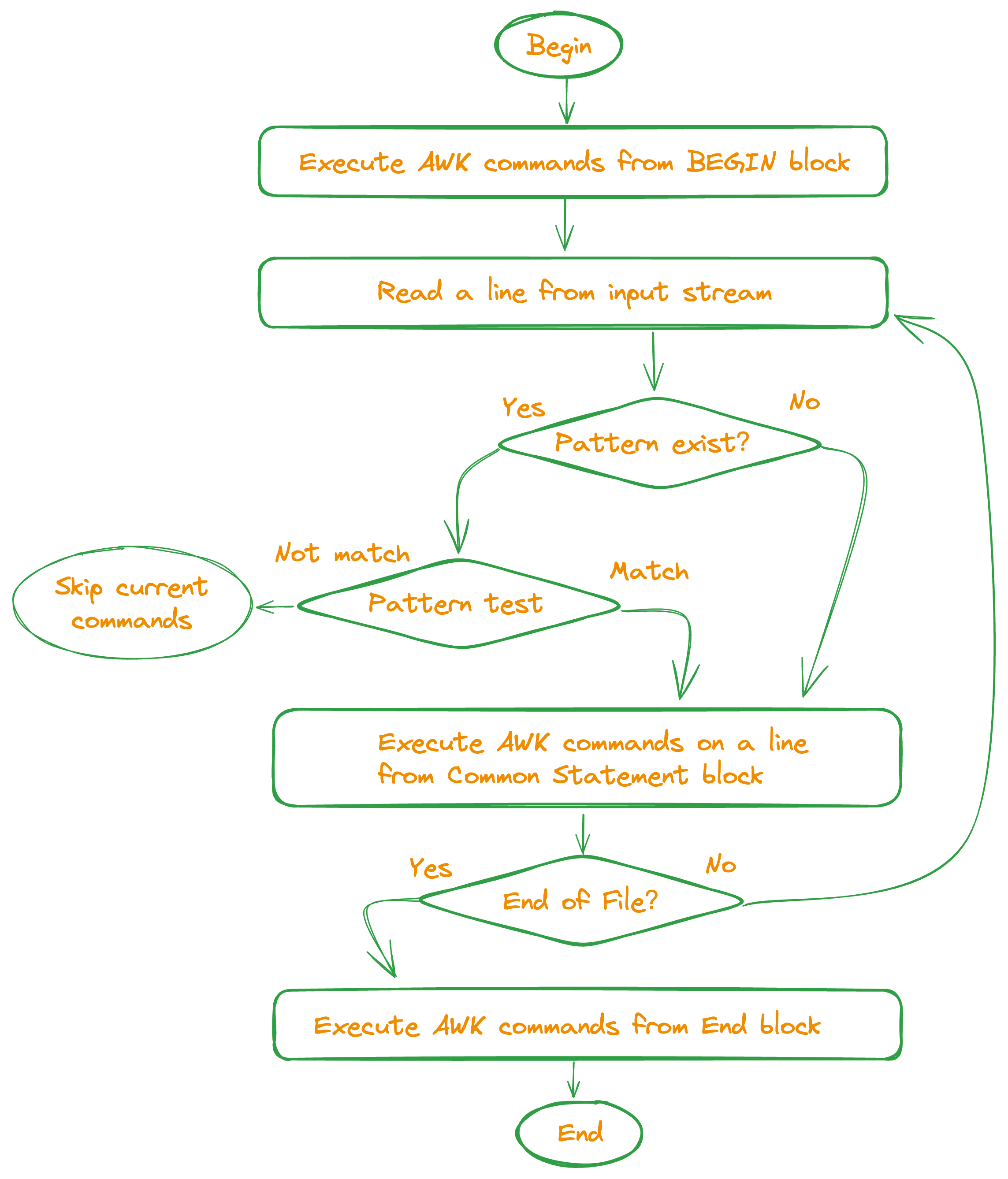
执行流程
理解此部份内容是开发 AWK 脚本的关键步骤。
AWK 脚本执行时,首先执行 BEGIN block 的内容,然后从文件(或stdin)中读取一行数据,依次检查是否匹配 Common Statement block
中定义的 pattern,如果匹配则执行该 pattern 对应的 commands 程序块,缺省 pattern 表示总是匹配,缺省的 commands 表示打印当前行,
一直这样重复地读取数据然后匹配处理,直到文件末尾,最后执行 END block 的内容。
AWK 脚本的执行流程图如下:
内建变量
在 AWK 脚本中,有一些变量的值由 awk 解释器维护,在程序中可以直接引用,这部分变量称为内建变量(Build-in variables)。
通过这些内建变量,可以获取到输入数据并进行处理。
Body block 中,内建变量 $0 表示本次处理的整行数据,$1 $2 $3 … 分别表示行内的第一、二、三个(默认空格分隔)数据。
常用的内建变量列表:
| Variables | Long Name | Description |
|---|---|---|
| $0 | 整行数据 | |
| $1, $2…$NF | 行内的第一个,第二个…最后一个字段(默认按空格分隔) | |
| NR | Number of Records | 当前处理数据的行号 |
| NF | Number of Fields | 当前处理数据的的总列数 |
| RS | input Record Separator | 输入行的分隔符,默认为换行符 |
| FS | input Field Separator | 输入列的分隔符,默认为空格 |
| ORS | Output Record Separator | 输出行的分隔符,默认为换行符 |
| OFS | Output Field Separator | 输出列的分隔符,默认为空格 |
| FILENAME | 当前输入数据的文件名 | |
| ARGC | Arguments Count | 命令行参数数量 |
| ARGV | Arguments Variable | 命令行参数列表 |
| ENVIRON | Environment | 环境变量字典 |
关于输入分隔符,对输入的数据,首先用RS分隔成 Records,再使用FS分隔成 Field,由于默认分隔符为换行和空格,
所以有了行 $0 与 列 $1...n 的概念。

在复杂的文件解析处理任务中,按实际场景合理的自定义RS FS,能有效地降低文本解析处理的难度。
语法
pattern
前文说到,Body block 写为 <pattern 1> {<commands>} 的形式,如果输入行匹配 pattern 则执行 {} 内的 commands。
pattern 表达式的写法有:
| Pattern | Description |
|---|---|
| $1 == “foo” | 行内第一个元素(默认按空格分隔,下同)的值为 foo |
| $1 != “foo” | 行内第一个元素的值不为 foo |
| /regex/ | 整行匹配正则表达式 regex |
| !/regex/ | 整行不匹配正则表达式 regex |
| $1 ~ /regex/ | 行内第一个元素的值匹配正则表达式 regex |
| $1 !~ /regex/ | 行内第一个元素的值不匹配正则表达式 regex |
| $1 <= 100 || $2 > 20 | 第一个元素的值小于等于 100 或第二个元素的值大于 20 |
| $1 <= 100 && $2 > 20 | 第一个元素的值小于等于 100 且第二个元素的值大于 20 |
| !($1 <= 100 && $2 > 20) | 对条件取反 |
| NR > 3 | 仅处理行号大于3的数据 |
| NF > 3 | 仅处理列数大于3的行 |
| $1 * $2 > 100 | 第一个元素和第二个元素的积大于 100 的行 |
引言中查找 PID 的示例 awk '/Google Chrome/{print $1}' 就用到了 /regex/ pattern。
变量
变量名可以是语言关键字外的,只包含大小写拉丁字母,数字和下划线(“_”)的任意字。
操作符+ - * /则分别代表加,减,乘,除。简单的将两个变量(或字符串常量)放在一起,则会将二者串接为一个字符串。
若二者间至少有一个是常量,则中间可以不加空格;但若二者均为变量,中间必须包括空格。字符串常量是以双引号 " 分隔的。
定义 foo 变量并与输入组合后打印:
| |
输出:
| |
数组
数字索引的数组:
多维数组
SUBSEP 多维数组键的分隔符, 文档 :
字符串索引的数组:
预置函数
预置函数是 awk 解释器内置的标准函数,无需要定义,可以直接使用。常用的预置函数有:
| Function | Description |
|---|---|
| index(s,t) | 返回子串 t 在 s 中的起始位置(从 1 开始计数),子串 t 不在 s 返回 0 |
| match(s,r) | 返回正则表达式 r 在 s 中的起始位置(从 1 开始计数),不匹配则返回 0 |
| sub(r,t,s) | 将字符串 s 中第一次出现的匹配正则表达式 r 的内容替换为 t |
| gsub(r,t,s) | 将字符串 s 中所有匹配正则表达式 r 的内容替换为 t |
| length(s) | 返回字符串 s 的长度 |
| substr(s,idx,len) | 返回字符串 s 的子串 s[index, idx + len),(index 从 1 开始计数) |
| split(s,arr,fs) | 把字符串 s 的按分隔符 fs 分隔后,存储在数组 arr 中 |
| tolower(s) | 将字符串 s 转为小写 |
| toupper(s) | 将字符串 s 转为大写 |
| system(cmd) | 执行 cmd 命令并返回命令的退出状态码 |
| int(x) | 返回 x 的整数 |
| getline | 将 $0 设置为当前输入内容中的下一行输入记录 |
使用示例:
用户自定义函数
新建 cube.awk 并赋予文件可执行权限:
执行输出:
控制流
if
if-else
if-else-if
switch
switch 仅 GNU 版本2的 awk 支持。
循环
for
如打印数字 1 到 10:awk 'BEGIN { for (i = 1; i <= 10; ++i) print i }'
while
如打印数字 1 到 10:awk 'BEGIN { i = 1; while (i <= 10) { print i; ++i } }'
do-while
如打印数字 1 到 10:awk 'BEGIN {i = 1; do { print i; ++i } while (i <=10 ) }'
exit loop
break语句用于结束循环的执行;continue语句用于结束本次循环,开始下一次循环;exit停止脚本的执行。它接受一个整数作为参数,这将是AWK进程的退出状态代码。如果没有提供任何参数,退出返回状态为零。 在非 END 块中执行exit会跳转到 END 块执行;next用于在Common Statement block中停止当前正在处理的行(record),开始下一行的处理;return [ expression ]用于在函数中返回值。
案例
要求实现一个AWK脚本,以表格方式显示主机的网络信息,包括设备名称和 IP 地址信息。
使用ifconfig输出的信息如下:
| |
相应的awk解析脚本eth.awk:
执行脚本ifconfig | awk -f eth.awk,输出:
前文中提到,对于输入的数据,awk是首先用RS分隔成 Records,Records 再被FS分隔成 Field,RS FS 默认分别为换行和空格,
此时的 Records 是行,Field 是列,直观上让人感觉awk是在按行和列处理文本。
ifconfig输入的信息中,由于网络设备名称和其IP信息并不在同一行中,按行来解析处理信息后再汇总会很麻烦,
所以此处进行了行列重定义,即把 Records 分隔符RS设置为空行""3,把 Field 分隔符设置为换行符\n。
这样设备名称和其IP信息被分隔在了同一个 Records 中,设备名称在第一个 Field,
如 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 65535,
IP信息在第二个 Field,如 inet 172.17.0.2 netmask 255.255.0.0 broadcast 172.17.255.255。
再使用split函数把 Field 的数据分隔成数组,通过数组索引拿到设备名,IP等数据。
本示例的核心要点在于通过自定义RS FS进行了行列重定义,把相关的信息都集中在同一个 Records 中处理,从而简化了解析逻辑。
总结
理解awk的
执行流程
和RS FS
分隔符
是用好awk的核心和关键。
功能上,awk不仅仅是只能取文本的某一列这么简单,而是同bash一样是一个脚本解释器,可以使用 AWK 脚本完成复杂的文本解析处理任务。
效率上,相比于使用纯bash脚本解析文本,awk在同一个上下文中解析文本,减少了上下文切换,会极大地提升文本解析的效率。
期望本文能让你认识到一个不一样的awk。
参考
- wiki https://zh.wikipedia.org/wiki/AWK
- gawk https://www.gnu.org/software/gawk/
- AWK程序设计语言 https://awk.readthedocs.io/
- quickref https://quickref.me/awk
- tutorialspoint https://www.tutorialspoint.com/awk/
推荐使用
pgrep命令更简单地获取 PID,本例为演示效果使用了awk, 适用于pgrep命令未安装情况。 ↩︎AWK 解释器有多个版本的实现 , 通常使用的是 GNU 版本。 ↩︎
input record separator (default newline). If empty, blank lines separate records. If more than one character long, RS is treated as a regular expression, and records are separated by text matching the expression. (from
man awk) ↩︎